
HA Introduction
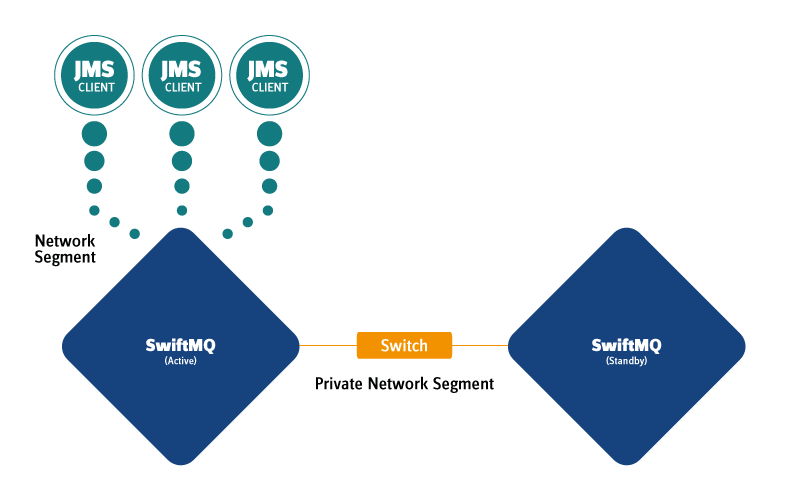
SwiftMQ High Availability (HA) Router is fully based on SwiftMQ Universal Router and provides High and Continuous Availability to JMS clients. It consists of 2 HA instances, deployed on different hosts in an ACTIVE/STANDBY fashion. The ACTIVE instance serves JMS and routing connections and synchronously replicates its state over a replication connection to the STANDBY instance.
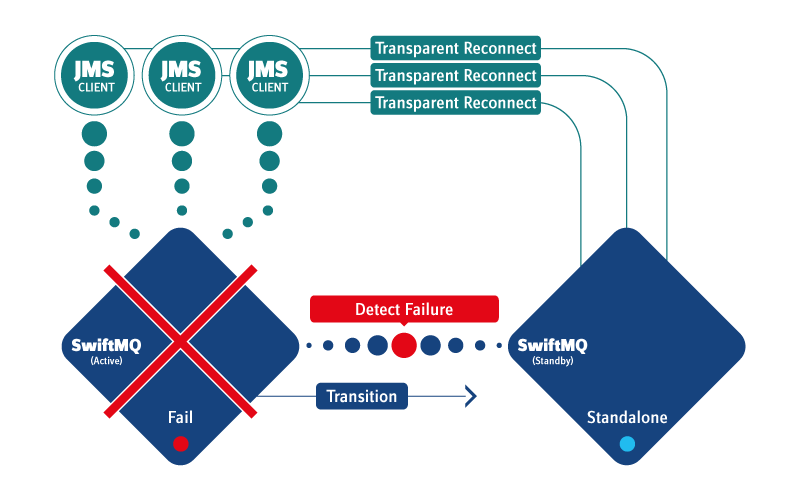
If the ACTIVE instance fails or is shut down, the STANDBY resumes operation, and JMS clients and routing connections transparently reconnect to this instance without persistent message loss or duplicate message delivery. There is no reconnect code required in JMS clients because their whole state of connections, sessions, producers, and consumers is recreated during reconnect. Open transactions, including prepared XA transactions (in-doubt transactions), are resolved and automatically recovered. Operation continues at that point where it stops before the failover.
High Availability
The term "High Availability" usually refers to unplanned outages and to transparently resume operation in case of such a failure. This is fully supported by SwiftMQ HA Router by its ACTIVE/STANDBY configuration as described above.
Continuous Availability
"Continuous Availability" extends "High Availability" with planned outages, especially version upgrades. This is fully supported through versioning. SwiftMQ has protocol versioning on all protocols including the replication protocol between HA instances. This enables customers to upgrade a SwiftMQ HA Router during operation without interruption.
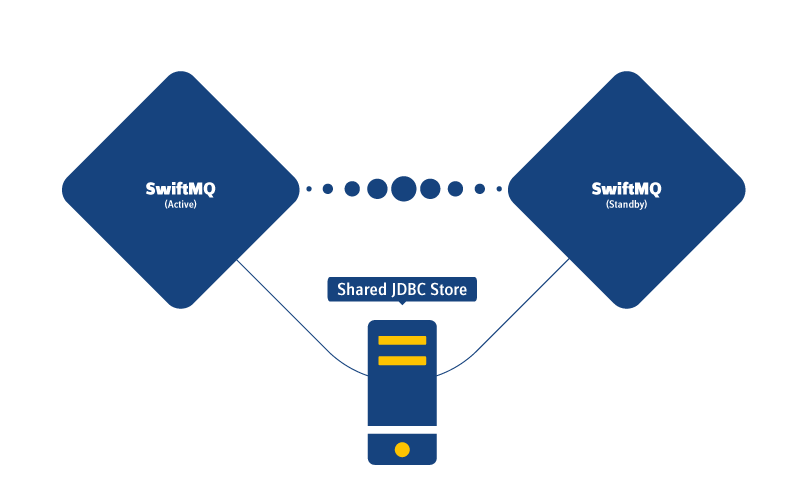
Choice of Persistent Store
SwiftMQ HA Router supports 3 different types of persistent stores:
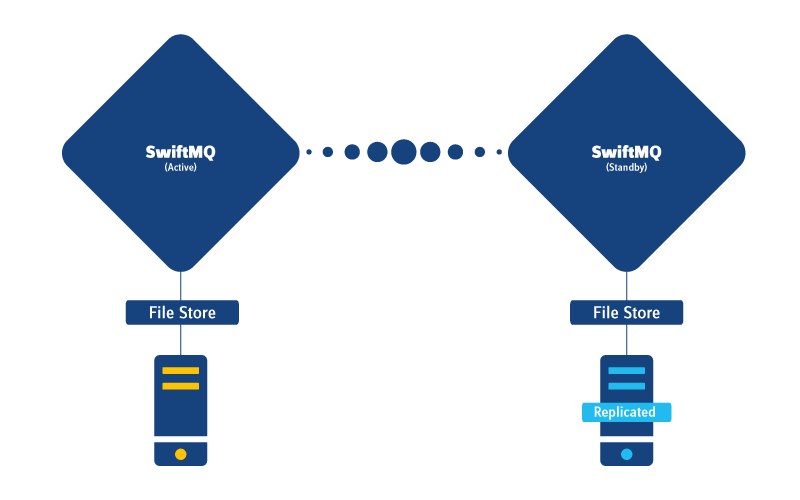
Replicated File Store
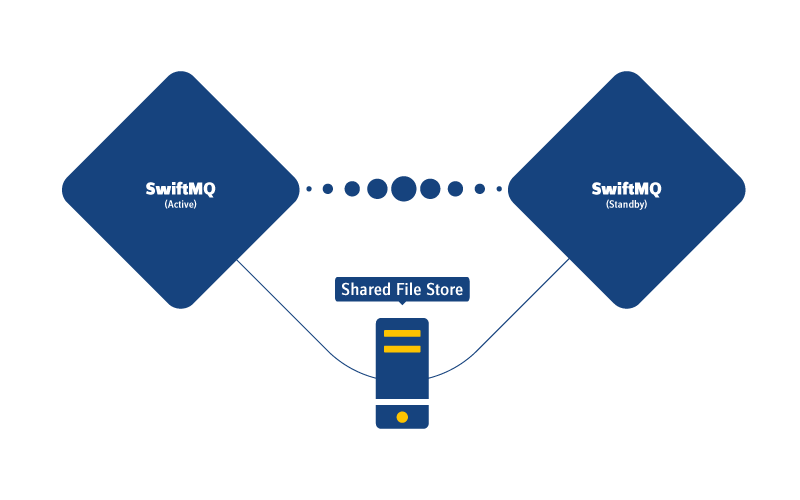
Shared File Store
Shared JDBC Store
A Replicated File Store consists of 2 replicas, a master at the ACTIVE instance, and a copy at the STANDBY. An image of the complete store is copied to the STANDBY during connect. Subsequently, the transaction log will be synchronously replicated, so that the STANDBY is always in a consistent state. Although it seems expensive to replicate the whole store and the transaction log, a Replicated File Store is quite fast and does not require any special and expensive hardware.
A Shared File Store uses a shared directory for the persistent store. This directory must reside on a shared RAID or SAN with a high-performance network. The transaction log must use disk sync that requires expensive hardware in order to get acceptable performance. Since it is shared, no store replication is required between the HA instances.
A Shared JDBC Store uses the same database for both HA instances. To avoid a single point of failure, this database should be clustered as well. A Shared JDBC Store doesn't require store replication between HA instances.
Transparent JMS and JNDI Failover
JMS and JNDI connections are automatically reconnected to the other HA instance when a connection loss is detected. During reconnect, the whole client state is recreated and the operation continues. This failover is transparent to clients. Reconnect code is not required.
Failback
After a failover and when the stopped HA instance comes back up as STANDBY, a failback can be initiated by restarting the ACTIVE HA instance. One of the HA instances can be declared as "preferred active" which will automate this process. For example, if the ACTIVE should always run on a faster machine and the STANDBY on a slower backup machine, the HA instance at the faster machine will be the preferred active and SwiftMQ initiates an automatic failback once this HA instance comes back up. This is completely transparent to JMS clients and does not require any administrative actions!
Automatic Recovery of in-doubt Transactions
All kinds of transactions in transit are automatically recovered during reconnect. This includes local transactions (e.g. commit/rollback sent but reply not yet received), XA transactions (in-doubt transactions; prepared but not committed) as well as non transacted sessions with any acknowledgment mode.
Duplicate Message Detection
When a failover happens while a producer sends messages and did not receive a receipt from the router, it must send them again. This can lead to duplicate messages. The same can happen on the consumer side where the new HA instance doesn't know whether the client did receive messages already after a failover if the client wasn't able to reply to delivery requests before failover. This becomes a very complex issue in JMS scenarios involving rollbacks, session recovery, and XA. SwiftMQ has full duplicate message detection at the router and the client-side and ensures that no message is delivered twice and no persistent message is lost.
Transparent Reconnect from CLI, CLI Admin API
SwiftMQ's administration tools CLI, and CLI Admin API automatically reconnects like any other JMS client. Additionally, they recreate their internal management state by interacting with the Management Swiftlet of the new HA instance. All tools have additional commands to start/stop HA instances and to save the configuration. Configuration changes are automatically replicated to the STANDBY instance, so both instances have always the same configuration.
High Availability Test Suite
Testing your application under HA conditions without tools can be painful if the HA instances must be stopped and started manually. The distribution contains a complete HA test suite, consisting of launchers and monitor tools to start and stop HA instances in intervals, thus making tests very easy.